
Regulatory reporting automation is defined as the use of technology to collect, validate, and submit compliance data to regulatory bodies with minimal manual intervention. For risk managers and compliance officers at community banks, credit unions, and lenders, the role of automation in regulatory reporting has shifted from a convenience to a core operational requirement. Over half of financial firms cite manual workflows as their primary reporting challenge. That figure reflects a sector under real pressure, where fragmented data, tight deadlines, and rising regulatory expectations make manual processes a liability rather than a baseline.
How does automation transform the regulatory reporting workflow?
Regulatory reporting automation works by replacing manual steps across four distinct phases: data extraction, rule-based validation, anomaly detection, and report compilation. Each phase carries its own risk profile. Automating only one phase while leaving others manual creates gaps that regulators and auditors will find.
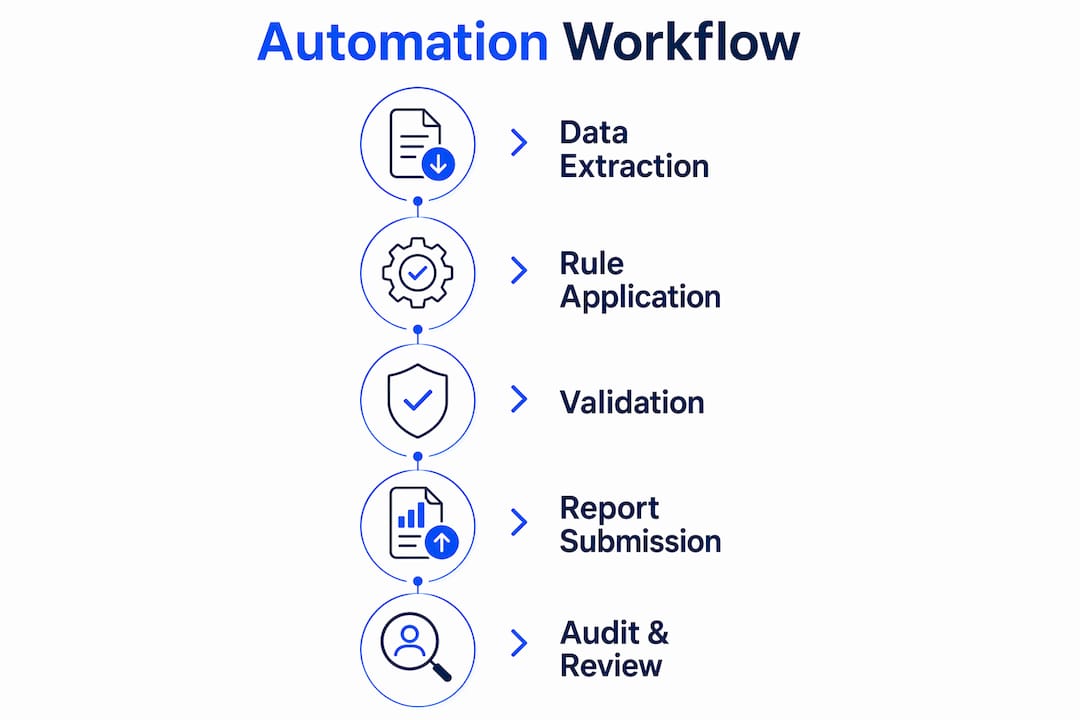
The distinction between automating the data pipeline and automating the output formatting phase matters significantly. Data pipeline automation handles extraction, normalization, and validation at the source. Output formatting automation handles the final assembly of reports into required templates, such as XBRL or CSV formats required by the FCA, PRA, or Federal Reserve. Both phases need automation, but the data pipeline carries higher risk if left manual.

Scale makes this clear. Mid-sized banks submit over 100 different regulatory returns annually across multiple agencies. Managing that volume manually means dozens of staff hours spent on repetitive data pulls, cross-checks, and formatting tasks every reporting cycle. Automation converts that recurring burden into a governed, repeatable process.
The practical steps for building an automated reporting workflow follow a logical sequence:
- Map your data sources. Identify every system that feeds regulatory data, including core banking platforms, loan origination systems, and general ledgers.
- Define validation rules centrally. Write rules once and apply them consistently across all returns to avoid duplicated logic.
- Build anomaly detection checkpoints. Flag outliers before reports reach the submission stage, not after.
- Automate report compilation. Use templates aligned to agency requirements to generate outputs directly from validated data.
- Schedule submissions with audit trails. Log every data transformation and submission event for traceability.
Pro Tip: Start automation with your highest-frequency, most complex returns first. These carry the greatest manual risk and deliver the fastest measurable return on your automation investment.
Why is risk reduction the real measure of automation success?
Speed is the visible benefit of automation. Risk reduction is the one that matters most to regulators and audit teams. Treating automation as a speed project alone often redistributes risk to compliance and audit teams rather than eliminating it. That is a critical distinction for any compliance officer building a business case for automation investment.
Governed data layers are the foundation of risk-reducing automation. When reporting draws from a single, controlled data environment with defined lineage, fragmentation disappears. Auditors can trace every figure back to its source. Regulators receive consistent, explainable outputs. That traceability is what separates automation that reduces risk from automation that merely accelerates it.
"Effective automation must treat reporting as an extension of operational data layers, with single rule definitions reused consistently to avoid fragmented logic and duplicated effort." — Automating Regulatory Reporting Without Losing Control
Embedded validation and evidence within workflows maintain consistent, auditable reporting far more reliably than post-process checks. Post-process checks catch errors after data has already moved through the pipeline. Embedded validation stops errors at the point of entry. For a compliance officer facing an FCA or OCC examination, that difference is the difference between a clean audit and a remediation exercise.
The deeper gain from well-governed automation is institutional trust. When your data is traceable, your reports are defensible, and your audit trail is complete, the conversation with regulators shifts from justification to confirmation.
What role does AI play in regulatory reporting automation?
AI extends automation beyond rule execution into pattern recognition and adaptive rule management. In a regulatory reporting context, AI performs three functions that static rule engines cannot: data aggregation across heterogeneous systems, dynamic rule mapping as regulations change, and anomaly detection that flags inconsistencies before submission.
The practical value of AI anomaly detection is significant. AI-driven regulatory reporting workflows reduce errors by 60%–90% in complex regulatory filings. That reduction comes from AI identifying data mismatches, missing fields, and threshold breaches that a human reviewer would likely miss under time pressure.
Key AI functions in a well-governed reporting environment include:
- Data normalization. AI aggregates data from multiple source systems and maps it to a consistent schema before validation begins.
- Rule mapping. AI tracks regulatory rule changes from bodies like the Basel Committee, FASB, or CFPB and updates validation logic accordingly.
- Anomaly flagging. AI surfaces outliers and inconsistencies for human review before reports are compiled.
- Continuous monitoring. AI supports event-driven reporting models where data is monitored in real time rather than assembled at period end.
The governance constraint is non-negotiable. AI must be embedded within governance frameworks to prevent black-box decisions that regulators cannot interrogate. Explainability is not optional when the output is a regulatory filing. Every AI-generated flag or adjustment must be traceable to a defined rule or data condition.
Pro Tip: Require your AI layer to produce an audit log for every anomaly it flags and every rule it applies. Regulators increasingly expect explainable outputs, not just accurate ones.
What are the best practices for implementing regulatory reporting automation?
Effective implementation starts with data governance, not technology selection. Disconnected reporting layers and manual interventions reintroduce the exact risks automation is meant to remove. Building automation on top of fragmented data sources produces fragmented outputs, regardless of how sophisticated the automation layer is.
Human review checkpoints are not a sign of incomplete automation. They are a design feature. In automated environments, data quality failures propagate at machine speed, making human judgment at defined review points a critical control. A well-designed workflow includes exception-based delivery, where only flagged items reach a human reviewer, rather than routing every report through manual sign-off.
The table below contrasts common implementation approaches across key design dimensions:
| Design dimension | Fragmented approach | Governed approach |
|---|---|---|
| Data sourcing | Multiple manual extracts per cycle | Single governed data layer with defined lineage |
| Rule management | Rules duplicated across systems | Single rule definitions reused across all returns |
| Validation timing | Post-process checks after compilation | Embedded validation at data ingestion |
| Human review | Full manual review of every report | Exception-based review of flagged items only |
| Audit trail | Reconstructed after the fact | Logged automatically at every workflow step |
| Access controls | Shared credentials, broad access | Role-based access with full activity logging |
Common pitfalls follow predictable patterns. Duplicated logic across systems means a rule change must be applied in multiple places, and one missed update creates a discrepancy. Disconnected data layers mean the same figure can appear differently in two returns submitted to the same regulator. Fragmented outputs mean your audit trail has gaps that examiners will find.
Starting with your most painful returns and expanding is the right sequencing strategy. It builds internal confidence, surfaces governance gaps early, and delivers measurable risk reduction before you scale.
Key takeaways
Automation reduces regulatory reporting risk most effectively when it is built on governed data, embedded validation, and defined human oversight checkpoints rather than speed alone.
| Point | Details |
|---|---|
| Governance before technology | Build automation on a single, controlled data layer before selecting tools or platforms. |
| Embed validation early | Validate data at ingestion, not after report compilation, to prevent errors from propagating. |
| AI requires explainability | Every AI-generated flag or rule application must produce a traceable audit log for regulators. |
| Human oversight is a design feature | Exception-based human review at defined checkpoints reduces risk without slowing throughput. |
| Start with the hardest returns | Automating high-frequency, complex returns first delivers the greatest risk reduction fastest. |
The compliance landscape is changing faster than most firms realize
The shift from periodic to continuous regulatory reporting is not a future trend. Regulators in the UK, EU, and US are actively piloting near-real-time data submission models. That shift changes the fundamental architecture of compliance. A firm built on quarterly batch processes will not adapt by adding more automation to a fragmented pipeline. It needs a governed data environment that treats reporting as an ongoing operational output, not a periodic project.
What I find most telling in conversations with compliance officers is the gap between firms that treat automation as a reporting tool and those that treat it as a data governance initiative. The first group gets faster reports. The second group gets defensible ones. Regulators care about the second outcome, not the first.
The firms that will manage continuous reporting requirements well are those that have already embedded single rule definitions, traceable data lineage, and exception-based review into their current workflows. Speed will follow from that foundation. Chasing speed without it produces faster errors, not better compliance.
AI adds real value in this environment, particularly for anomaly detection and adaptive rule mapping. But AI without governance is a liability in a regulatory context. The explainability requirement is not going away. If your AI layer cannot tell an examiner why it flagged a specific data point or applied a specific rule, you have a governance gap, not a technology advantage.
The firms that get this right treat their compliance officers not as report producers but as data stewards. That reframe changes everything about how automation gets designed and deployed.
— Raj
Riskinmind's approach to automated compliance reporting
Riskinmind builds AI-powered risk management tools specifically for credit unions, community banks, and lenders that need governed, auditable compliance workflows. The platform's AI agents handle data validation, anomaly detection, and report generation within a SOC 2® certified environment, with response times under half a second.
For risk managers evaluating where to start, Riskinmind's loan application automation tools connect regulatory data requirements directly to origination workflows, reducing manual data handling at the source. The peer benchmarking and risk analysis product supports regulatory accuracy by giving compliance officers context on portfolio risk relative to peer institutions. Both tools are designed for professionals who need defensible outputs, not just faster ones. You can also explore Riskinmind's broader thinking on automated compliance investment to build your internal business case.
FAQ
What is regulatory reporting automation?
Regulatory reporting automation is the use of technology to collect, validate, and submit compliance data to regulatory bodies with minimal manual intervention. It replaces manual data extraction, rule application, and report formatting with governed, repeatable workflows.
Why automate regulatory reporting?
Over half of financial firms identify manual workflows as their primary reporting challenge. Automation reduces operational risk, improves audit traceability, and handles the volume and complexity of modern regulatory requirements more reliably than manual processes.
How does automation improve compliance accuracy?
AI-driven workflows reduce errors by 60%–90% in complex regulatory filings by normalizing data, applying rules consistently, and flagging anomalies before submission. Embedded validation at the data ingestion stage prevents errors from reaching the final report.
What is the biggest risk of regulatory reporting automation?
The biggest risk is redistributing rather than eliminating operational risk. Automation built on fragmented data layers or without embedded validation moves risk from operations to audit teams, where it is harder to detect and more costly to remediate.
How do you streamline regulatory audits with automation?
Automating audit trails at every workflow step, using role-based access controls, and embedding validation directly into data pipelines gives auditors a complete, traceable record. Exception-based delivery ensures human reviewers focus on flagged items rather than reviewing every report manually.