
Predictive analytics for credit is defined as the application of historical borrower and loan data combined with statistical algorithms and machine learning models to generate probabilistic forecasts of future credit outcomes, most critically the probability of default. This discipline sits at the core of modern lending decision-making, enabling credit risk analysts and finance professionals to move beyond backward-looking reporting toward forward-looking risk quantification. Where traditional credit scoring relied on static scorecards, today's predictive models incorporate dynamic feature sets, real-time data pipelines, and regulatory-grade calibration. The result is a credit risk function that can price risk accurately, stage loans correctly under IFRS 9, and approve or decline applications within milliseconds.
What is predictive analytics for credit: core concepts and metrics
Predictive analytics works by training models on historical cases with known outcomes and applying them to new borrower data to generate probabilistic future forecasts. In the credit context, those forecasts center on three foundational risk metrics that every analyst must understand.
Maintain 100% NCUA & OCC Audit Readiness
Monitor regulatory updates 24/7, check internal credit policies, and generate compliance trails with Erina (AI Regulatory Agent).
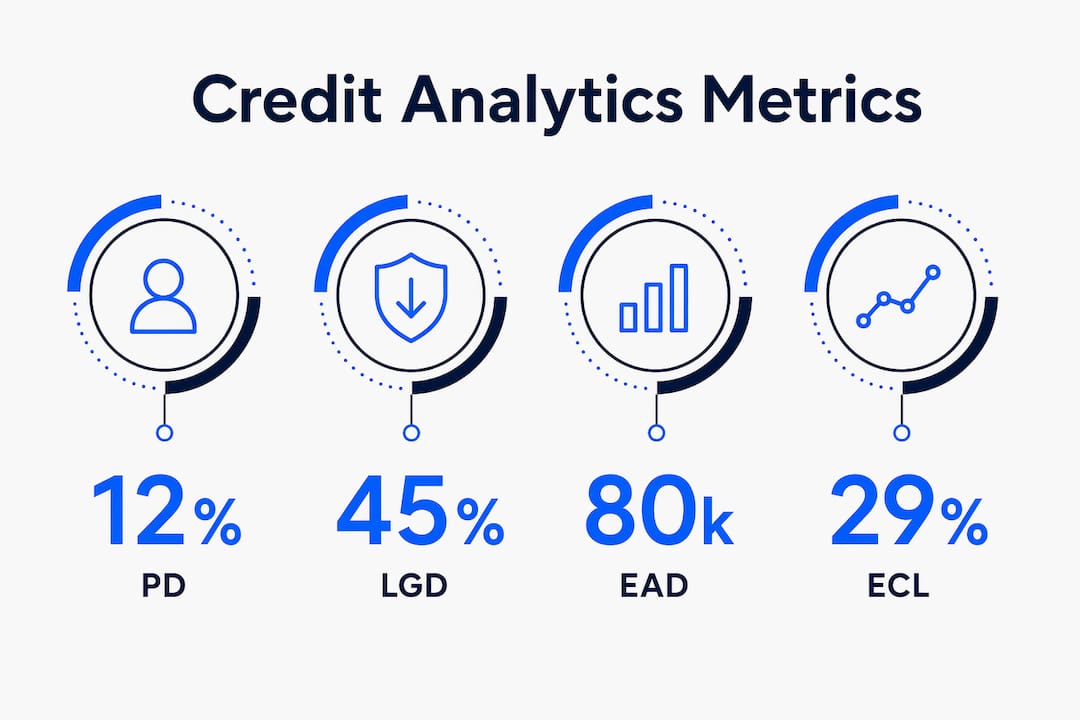
Probability of Default (PD) measures the likelihood that a borrower will fail to meet contractual obligations within a defined time horizon. Loss Given Default (LGD) quantifies the share of exposure the lender expects to lose if default occurs, after accounting for collateral recovery. Exposure at Default (EAD) captures the outstanding balance at the moment of default, including undrawn commitments on revolving facilities.
These three metrics combine into the Expected Credit Loss formula: ECL = PD × LGD × EAD. Under IFRS 9, the PD input is not a single number but a term structure. Stage 1 loans use a 12-month PD, while Stage 2 and Stage 3 loans require lifetime PD, reflecting the significant increase in credit risk since origination. This distinction matters enormously for allowance calculations and financial reporting accuracy.
The modeling methods used to estimate PD range from logistic regression and survival analysis to gradient boosting frameworks such as XGBoost and deep neural networks. Classification models output a default probability score; regression models may estimate LGD or EAD directly. For machine learning in finance, the choice of algorithm depends on data volume, interpretability requirements, and regulatory tolerance for model complexity.
| Metric | Definition | IFRS 9 Application |
|---|---|---|
| PD (Probability of Default) | Likelihood of borrower default over a time horizon | 12-month for Stage 1; lifetime for Stages 2 and 3 |
| LGD (Loss Given Default) | Expected loss rate post-default, net of recovery | Applied uniformly across stages |
| EAD (Exposure at Default) | Outstanding balance at time of default | Includes undrawn commitments on revolving credit |
| ECL (Expected Credit Loss) | PD × LGD × EAD | Drives loan loss provisioning under IFRS 9 |
Pro Tip: Use PD term structures rather than single-point default probabilities. Marginal default probabilities across a loan's full life are required for accurate ECL computation and correct IFRS 9 staging, and collapsing them into a single figure introduces systematic provisioning error.
Regulatory and governance requirements for credit risk models
Regulatory expectations for predictive credit models have grown substantially more demanding under CRR3 and the ECB's internal models framework. The ECB's internal models guide requires that PD estimates be calibrated to long-run average default rates, with documented processes for internal validation, audit readiness, and data governance. These are not aspirational standards. They are supervisory requirements with direct capital implications.
Model governance in this context means more than having a validation team review model performance annually. It requires documented data lineage, feature engineering logs, out-of-time testing results, and evidence that model outputs remain stable across economic cycles. Regulators specifically scrutinize whether calibration holds when default rates deviate from the long-run average used in model development.
The following governance elements are non-negotiable for any institution using internal models under CRR3:
- Internal validation independent of model development, with documented challenge processes
- Calibration reports comparing realized default rates to model-estimated PD by segment and vintage
- Data governance controls covering input schema integrity, missing value treatment, and outlier handling
- Model drift monitoring that tracks probability output distributions over time, not just rank-ordering metrics like AUC
- Audit trails supporting regulatory examination and internal audit review
"Regulatory standards require predictive credit models to be robustly governed, internally validated, and aligned with supervisory expectations including CRR3 for consistent internal model use." — ECB internal models guidance
Misalignment between model horizons and IFRS 9 staging rules is one of the most common and consequential errors in practice. When a model trained on 12-month outcomes is applied to a Stage 2 portfolio requiring lifetime PD, the ECL estimate is structurally understated. This distorts both financial reporting and capital adequacy assessments.
Pro Tip: Align model output horizons explicitly with IFRS 9 staging rules at the design stage. Retrofitting a 12-month PD model to produce lifetime estimates through scaling factors introduces calibration error that compounds across large portfolios.
How predictive analytics integrates into real-time lending workflows
The operational value of predictive analytics for loans is realized when model outputs are embedded directly into the loan origination process rather than used as a post-hoc review tool. Real-time scoring in 2026 digital lending platforms delivers inference results at the application interface within milliseconds, enabling pre-approval decisions, soft declines, and risk-based pricing without manual underwriter intervention.
The architecture supporting this capability typically involves the following components working in sequence:
- Data ingestion layer: Pulls traditional credit bureau data alongside alternative data sources including cash flow consistency from bank transaction feeds, professional trajectory signals from employment records, and payment behavior from utility and telecom providers.
- Feature engineering pipeline: Transforms raw inputs into model-ready features, applying standardization, encoding, and derived variable construction in real time.
- Model inference engine: Scores the application against the deployed PD model, returning a probability score and associated confidence interval within the sub-second window.
- Decision rules layer: Translates the model score into a concrete credit decision, applying approval thresholds, pricing tiers, and limit assignments defined by credit policy.
- Monitoring and logging layer: Records every scored application with its input features and output score for ongoing model monitoring, regulatory audit, and portfolio analytics.
Risk-based pricing is one of the most direct financial benefits of this architecture. When PD estimates are granular and well-calibrated, lenders can set interest rates that accurately reflect individual borrower risk rather than applying broad band pricing. This improves margin on lower-risk borrowers while maintaining adequate return on higher-risk segments. For credit unions and community banks, where relationship lending has historically limited pricing precision, this represents a material shift in how credit risk is monetized.
Pro Tip: Integrate AI loan underwriting tools that expose model scores and confidence intervals to underwriters, not just binary approve/decline outputs. Underwriters who understand the probabilistic basis of a decision make better exception judgments and provide higher-quality model feedback.
Descriptive, predictive, and prescriptive analytics: how they differ in credit
Understanding predictive analytics requires placing it within the broader analytics taxonomy used in credit risk management. The three types are complementary, not interchangeable, and each serves a distinct function in the credit decisioning pipeline.

Predictive analytics fundamentally differs from descriptive reporting by forecasting probable future outcomes rather than explaining past events. This distinction has direct operational consequences. A descriptive report showing that delinquency rates rose 40 basis points last quarter tells you what happened. A predictive model scoring your current pipeline tells you which borrowers are likely to become delinquent next quarter, before the loss is realized.
| Analytics Type | Primary Question | Credit Risk Application |
|---|---|---|
| Descriptive | What happened? | Portfolio delinquency reports, vintage analysis, loss history |
| Predictive | What will happen? | PD scoring, ECL forecasting, early warning signals |
| Prescriptive | What should we do? | Approval rules, pricing tiers, limit management, workout strategies |
Predictive model outputs serve as inputs to prescriptive decision rules rather than standing as decisions themselves. A PD score of 8% does not tell a lender to approve or decline. It tells the decision engine where this borrower sits relative to the policy threshold, which then determines the outcome. This pipeline structure, from descriptive data to predictive scores to prescriptive policy, is the operating model of every mature credit risk function.
The practical implication for credit risk teams is that investing in predictive modeling without investing equally in the prescriptive layer produces incomplete results. Model scores that do not feed into documented, governed decision rules create audit exposure and inconsistent credit outcomes. The loan risk modeling framework connecting these layers is as important as the model itself.
Key takeaways
Predictive analytics for credit generates its full value only when PD models are well-calibrated, regulatory-aligned, and embedded in governed lending workflows that connect probabilistic scores to concrete credit decisions.
| Point | Details |
|---|---|
| ECL formula drives provisioning | PD × LGD × EAD is the core calculation; IFRS 9 requires 12-month PD for Stage 1 and lifetime PD for Stages 2 and 3. |
| Regulatory governance is non-negotiable | CRR3 and ECB guidance require independent validation, calibration to long-run default rates, and full audit documentation. |
| Real-time integration unlocks operational value | Embedding model inference into loan application workflows enables millisecond scoring, risk-based pricing, and consistent credit decisions. |
| Analytics types are complementary | Descriptive, predictive, and prescriptive analytics form a pipeline; predictive scores must feed governed decision rules to produce outcomes. |
| Model monitoring goes beyond AUC | Calibration stability and probability usability at decision thresholds matter more than rank-ordering accuracy for financial reporting correctness. |
Why model operationalization is where most credit teams fall short
From my experience working with credit risk functions across community banks and credit unions, the gap between building a predictive model and deploying one that actually improves credit outcomes is wider than most teams expect. The technical work of model development, feature selection, and validation gets the attention. The operational work of connecting model outputs to decision systems, maintaining calibration through economic cycles, and documenting everything to audit standard gets underestimated.
The teams that extract the most value from predictive analytics are not necessarily the ones with the most sophisticated algorithms. They are the ones with tight data governance, where input schemas are controlled and changes are versioned, so that a feature definition shift does not silently corrupt model inputs six months after deployment. Errors in input schemas directly compromise financial reporting accuracy and model reliability, and they are far more common than model specification errors in production environments.
Model monitoring is the other area where I see consistent underinvestment. Tracking AUC over time gives you a rank-ordering metric. It does not tell you whether your PD estimates are still calibrated to realized default rates, which is what regulators and auditors actually care about. A model that ranks borrowers correctly but systematically underestimates default probability by 30% will produce understated ECL and create regulatory exposure. Calibration monitoring by segment and vintage, run quarterly at minimum, is the practice that separates institutions with defensible models from those with models that look good on paper.
The forward-looking reality is that predictive analytics for credit is becoming table stakes, not a competitive differentiator. What differentiates institutions is the quality of their model governance, the depth of their operational integration, and the speed at which they can retrain and redeploy models when economic conditions shift.
— Raj
How Riskinmind supports predictive analytics in credit workflows
Riskinmind's AI-powered platform is built specifically for the credit risk workflows described in this article, from real-time PD scoring at the loan application interface to portfolio monitoring and regulatory reporting.
The Loan Application product delivers sub-second credit scoring using neural networks and machine learning, integrating directly into origination workflows to enable risk-based pricing and consistent credit decisions at scale. For commercial real estate portfolios, the CRE Loan Risk Predictor applies predictive modeling to property-level and borrower-level data for more accurate risk segmentation. Riskinmind's platform also includes peer benchmarking tools that contextualize your portfolio's risk profile against comparable institutions, supporting both strategic credit policy decisions and regulatory examination preparation.
FAQ
What is predictive analytics for credit?
Predictive analytics for credit is the use of historical borrower and loan data combined with statistical models and machine learning to forecast future credit outcomes, primarily the probability of default. It enables lenders to quantify credit risk before a loss occurs rather than responding to it after the fact.
How is Expected Credit Loss calculated in predictive models?
ECL is calculated as PD multiplied by LGD multiplied by EAD. Under IFRS 9, the PD input varies by loan stage: Stage 1 uses a 12-month PD, while Stages 2 and 3 require lifetime PD to reflect elevated credit risk.
What regulatory requirements apply to predictive credit models?
The ECB's internal models guide and CRR3 require that PD estimates be calibrated to long-run average default rates, supported by independent internal validation, documented data governance, and full audit readiness. These requirements apply to institutions using internal ratings-based approaches for capital calculation.
How does predictive analytics differ from descriptive analytics in credit?
Descriptive analytics summarizes past credit performance, such as historical delinquency rates and loss trends. Predictive analytics forecasts future borrower behavior, generating probability scores that feed into approval, pricing, and limit decisions before losses materialize.
What data inputs do predictive credit models use?
Modern predictive credit models use traditional credit bureau data alongside alternative sources including bank transaction cash flow patterns, employment history, and payment behavior on non-credit obligations. The combination of traditional and alternative data improves model discrimination, particularly for thin-file borrowers with limited credit history.