
Machine learning in finance is defined as the application of algorithms that learn from historical financial data to automate decisions, detect anomalies, and forecast outcomes without fixed programming rules. Where traditional financial models rely on static equations and manually coded logic, ML systems adapt as new data arrives, making them fundamentally better suited to the nonlinear, high-dimensional nature of financial risk. The field spans supervised credit scoring models, unsupervised fraud detection, deep learning architectures like LSTM networks, and gradient-boosted classifiers like XGBoost. Regulatory frameworks such as SR 11-7 in the US and CRR3 in Europe now explicitly address how these models must be governed, validated, and monitored before deployment in material financial decisions.
What is machine learning in finance and where is it applied?
Machine learning in finance covers five core application domains, each with distinct model requirements and risk profiles.
Maintain 100% NCUA & OCC Audit Readiness
Monitor regulatory updates 24/7, check internal credit policies, and generate compliance trails with Erina (AI Regulatory Agent).
-
Credit risk scoring. ML models replace or augment traditional scorecards by capturing nonlinear relationships between borrower attributes and default probability. XGBoost and gradient-boosted trees consistently outperform logistic regression on out-of-sample default prediction because they handle interaction effects and missing data natively. The practical result is more accurate loan pricing and fewer unexpected charge-offs.
-
Fraud detection. Anomaly detection models flag transactions that deviate from a customer's established behavioral pattern in real time. Unlike rule-based systems that require manual threshold updates, ML models retrain on new fraud typologies as they emerge. This is why major card networks and payment processors have moved almost entirely to ML-based fraud scoring.
-
Algorithmic trading and market forecasting. Deep learning architectures, particularly LSTM networks, process sequential price and volume data to identify temporal dependencies that linear models miss. These models power high-frequency strategies as well as longer-horizon macro forecasting at asset managers and hedge funds.
-
Portfolio and asset management. LSTM networks combined with fuzzy clustering and portfolio optimization modules deliver superior return forecasting and dynamic capital allocation, significantly outperforming traditional benchmarks on Nasdaq data through 2024. The modular design separates forecasting from optimization, which simplifies risk constraint management.
-
Risk management and stress testing. ML captures nonlinear relationships between macro variables and credit losses that scenario-based models built on linear regression cannot represent. This matters most during tail events, when the relationships between risk factors behave least like their historical averages.
Pro Tip: When selecting an ML application for your institution, start with the use case where labeled historical data is most abundant and outcome definitions are clearest. Credit default prediction typically meets both criteria and provides the fastest path to a validated, production-ready model.
How does machine learning work technically in financial contexts?
Understanding the technical mechanics of ML in finance requires distinguishing between learning paradigms and recognizing why financial data creates unique modeling challenges.
-
Supervised learning trains a model on labeled historical examples, such as loans that defaulted versus those that did not, and learns to predict the label for new observations. XGBoost and neural networks are the dominant supervised methods in credit and fraud applications because they handle high-dimensional feature spaces and nonlinear interactions without manual feature engineering.
-
Unsupervised learning identifies structure in unlabeled data. Clustering algorithms group borrowers or assets by behavioral similarity, which supports portfolio segmentation, anomaly detection, and early warning systems where no explicit outcome label exists.
-
Deep learning for time series. LSTM networks and transformer-based architectures process sequential financial data by maintaining memory of prior observations. This makes them well-suited to price forecasting, volatility modeling, and macroeconomic nowcasting, where the order of observations carries predictive information.
-
Foundation models and transfer learning. Pre-trained time-series foundation models represent the frontier of financial ML, but financial time series data are noisy and non-stationary, requiring domain-specific pre-training rather than direct zero-shot application. Generic pre-training on non-financial data yields poor forecasting accuracy; finance-native pre-training and fine-tuning yield substantial accuracy and economic gains.
-
Regime shifts and temporal validation. Financial data changes character across economic cycles. A model trained on 2010 to 2019 data may perform poorly in a 2020 or 2022 stress environment. Rolling-window cross-validation and out-of-sample testing on held-out time periods are the standard defenses against this form of overfitting.
"Real-world financial ML success depends more on the quality and defensibility of input data and labels than on model complexity. Handling regime shifts requires careful temporal validation using rolling windows and out-of-sample testing." — Re(Visiting) Time Series Foundation Models in Finance
The practical implication for finance teams is that model architecture is rarely the binding constraint. Data quality, label integrity, and temporal validation discipline determine whether an ML model performs in production or fails quietly after deployment.
What governance and regulatory requirements apply to financial ML models?
Governance is not a post-deployment concern for ML in finance. It is a design requirement that shapes how models are built, documented, and monitored from the start.
-
SR 11-7 in the United States sets the standard for model risk management at federally supervised banks. SR 11-7 requires comprehensive governance including independent validation, model inventory maintenance, and ongoing performance monitoring for all quantitative models used in material decisions. ML models fall squarely within this scope, and examiners increasingly scrutinize whether validation artifacts address model complexity and not just accuracy metrics.
-
CRR3 and ECB guidance in Europe. The European Central Bank's 2025 FAQ updates on internal models explicitly require governance, data maintenance, explainability, and monitoring for ML models used in regulatory capital calculations. Explainability is a core regulatory requirement, not an optional enhancement, for any ML model used in material financial decisions.
-
Independent validation. Validation teams must assess model conceptual soundness, data integrity, and performance stability, not just in-sample fit. For ML models, this means stress-testing predictions under distributional shift and documenting how the model behaves when input data falls outside the training range.
-
Explainability artifacts. Regulators expect institutions to explain individual model outputs, not just aggregate performance statistics. Techniques like SHAP values and LIME provide feature-level attribution that satisfies this requirement for tree-based and neural network models.
Pro Tip: Build your model governance framework before you build your first production ML model. Retrofitting documentation, validation evidence, and monitoring infrastructure onto a deployed model is significantly more expensive and disruptive than designing for compliance from the start.
What recent advances are shaping the future of ML in finance?

The frontier of financial ML is moving faster than most governance frameworks can track, which creates both opportunity and institutional risk.
| Advance | Description | Practical Implication |
|---|---|---|
| Time-series foundation models | Large models pre-trained on financial time-series data | Finance-native pre-training required for accuracy gains |
| Generative models (GANs, diffusion) | Synthetic financial scenario generation | Expands stress-testing beyond historical scenarios |
| Reinforcement learning for robo-advisors | AI robo-advisors learn user risk tolerance from portfolio behavior | Outperforms static questionnaire-based profiling |
| Modular ML and optimization frameworks | Separate forecasting and optimization layers | Simplifies governance and risk constraint control |
| Zero-shot and transfer learning | Applying pre-trained models to new financial tasks | Currently unreliable without domain-specific fine-tuning |
The most consequential near-term development is the maturation of finance-specific foundation models. General-purpose time-series models trained on non-financial data perform poorly in zero-shot financial forecasting, but institutions that invest in domain-specific pre-training are seeing measurable accuracy and economic gains. The governance challenge is that these models are harder to validate using traditional SR 11-7 frameworks, which were designed for simpler parametric models. Regulators and institutions are actively developing updated validation standards to address this gap.
Generative models, particularly GANs and diffusion models, are gaining traction in stress testing because they can produce synthetic market scenarios that extend beyond the historical record. This matters for tail risk assessment, where the most damaging scenarios are precisely those that have not yet occurred.
How does ML compare to traditional financial modeling methods?
The comparison between ML and classical financial models is not a simple win for either side. Each approach carries distinct trade-offs that determine which is appropriate for a given application.
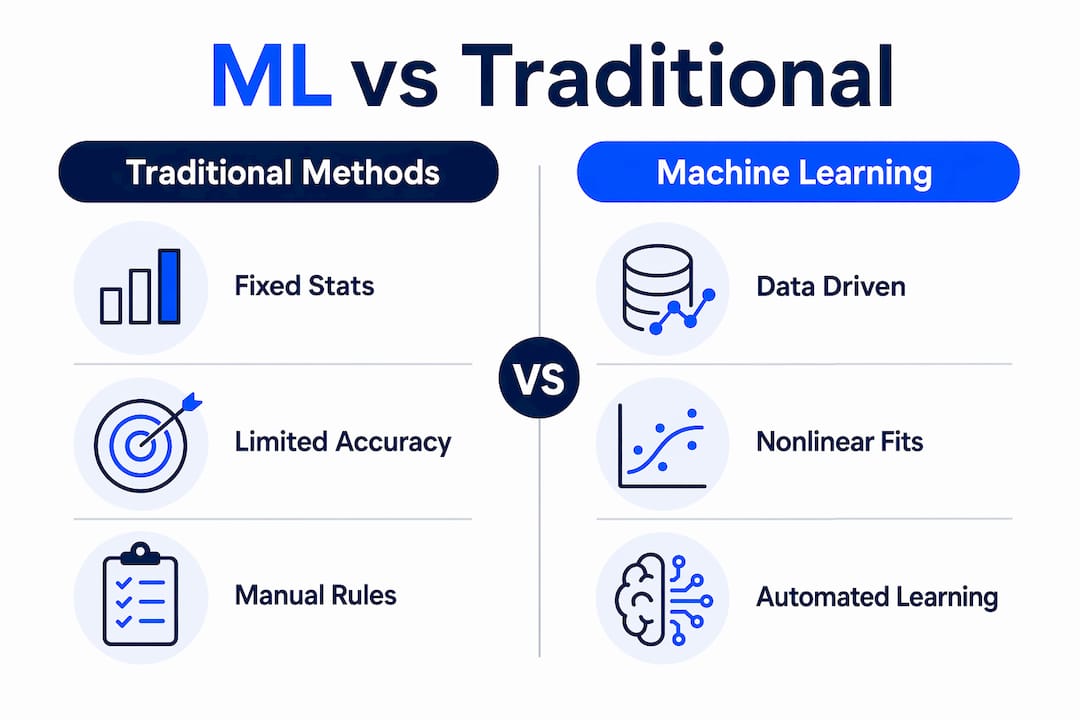
| Dimension | Traditional Methods | Machine Learning |
|---|---|---|
| Accuracy on nonlinear relationships | Limited by linear assumptions | Captures complex interactions natively |
| Explainability | High, by design | Requires additional techniques (SHAP, LIME) |
| Data requirements | Moderate, works with smaller samples | High, requires large labeled datasets |
| Regulatory acceptance | Well-established | Evolving, requires additional validation evidence |
| Adaptability to regime shifts | Requires manual recalibration | Can retrain automatically, but risks overfitting |
| Governance complexity | Lower | Higher, requires lifecycle monitoring |
Traditional logistic regression and linear discriminant analysis remain defensible choices for institutions with limited data or strong regulatory conservatism, because their outputs are directly interpretable and their validation requirements are well-understood. ML models earn their added governance burden only when the accuracy improvement is material and the institution has the infrastructure to support ongoing monitoring. Blending ML forecasts with classical portfolio optimization is the approach most commonly adopted by sophisticated asset managers, because it captures ML's predictive power while preserving the risk constraint control that classical optimization provides. The hybrid architecture also simplifies debugging when model behavior deviates from expectations.
Key takeaways
Machine learning in finance delivers its greatest value when domain-specific data quality, rigorous temporal validation, and lifecycle governance are treated as non-negotiable design requirements rather than afterthoughts.
| Point | Details |
|---|---|
| Core definition | ML learns from historical financial data to automate decisions without fixed programming rules. |
| Top applications | Credit scoring, fraud detection, algorithmic trading, portfolio management, and stress testing each use distinct ML architectures. |
| Technical constraint | Financial data is noisy and non-stationary; temporal validation with rolling windows is required to prevent overfitting. |
| Regulatory baseline | SR 11-7 and ECB CRR3 guidance require independent validation, explainability, and ongoing monitoring for all material ML models. |
| Hybrid advantage | Combining ML forecasting with classical optimization improves risk constraint control and simplifies governance. |
What practitioners get wrong about ML in finance
Working closely with financial institutions on ML deployment, the pattern I see most often is not a failure of model sophistication. It is a failure of data discipline and governance timing.
Teams spend months selecting between XGBoost and a transformer architecture, then discover six weeks before deployment that their training labels contain look-ahead bias or that their feature pipeline pulls data that would not have been available at the time of the original decision. The model is technically impressive and practically useless. The fix is not a better algorithm. It is a data audit conducted before model selection, not after.
The second consistent failure is treating explainability as a compliance checkbox rather than a diagnostic tool. Institutions that use SHAP values only to satisfy an examiner's request miss the real value: feature attribution tells you why a model is making the predictions it makes, which is the fastest way to catch data leakage, proxy discrimination, and distribution shift before they become examination findings or credit losses.
The third issue is governance timing. Responsible ML deployment depends on validated understanding of market dynamics, not just model accuracy. Institutions that build governance frameworks in parallel with model development, rather than retrofitting them afterward, consistently reach production faster and with fewer regulatory objections. The SR 11-7 lifecycle approach is not bureaucratic overhead. It is the fastest path to a model your board, your auditors, and your examiners will actually trust.
For credit union executives and CROs specifically: the question is not whether to adopt ML. The question is whether your validation infrastructure and data governance are ready to support it responsibly. If they are not, building that foundation first is the higher-return investment.
— Raj
See ML-driven risk analysis in action at Riskinmind
Riskinmind's AI-powered platform applies the machine learning principles covered in this article directly to the risk workflows that community banks, credit unions, and lenders manage every day. The CRE Loan Risk Predictor uses ML to assess credit risk in commercial real estate lending with greater accuracy than traditional appraisal-based models, delivering results in under half a second. For institutions that need portfolio-level context, the peer benchmarking tool provides AI-driven risk analytics that compare your institution's performance against relevant peers. Both tools are built on the same governance-first architecture described in this article, with SOC 2® certification and bank-grade security. Explore the platform to see how ML translates from theory to production-ready risk management.
FAQ
What is machine learning in finance, in simple terms?
Machine learning in finance is a method where algorithms learn patterns from financial data to make predictions or automate decisions, without being explicitly programmed for each scenario. Common examples include credit scoring, fraud detection, and portfolio forecasting.
What are the main benefits of machine learning in finance?
The primary benefits are improved accuracy on nonlinear prediction tasks, real-time processing of large data volumes, and the ability to adapt to new patterns without manual recalibration. ML also captures nonlinear risk-factor relationships that traditional linear models systematically miss.
What regulations govern ML models in financial institutions?
In the US, SR 11-7 requires independent validation, inventory maintenance, and ongoing monitoring for all material quantitative models, including ML. In Europe, ECB guidance under CRR3 adds explicit requirements for explainability and data governance for ML models used in regulatory capital calculations.
How does machine learning differ from traditional financial modeling?
Traditional models use fixed statistical relationships, while ML models learn those relationships directly from data and update as new data arrives. The trade-off is that ML requires more data, more rigorous validation, and additional explainability techniques to satisfy regulatory standards.
What is the biggest risk of using ML in financial decision-making?
The largest operational risk is model degradation during regime shifts, when the statistical relationships in training data no longer hold in live markets. Rigorous out-of-sample testing and continuous monitoring are the primary controls against this failure mode.