
Credit risk assessment has long forced a choice: optimize for accuracy, or optimize for fairness. Traditional scorecards do one reasonably well, rarely both. Machine learning challenges that framing directly, offering tools that process richer data, identify subtle risk patterns, and extend credit to borrowers who would otherwise be invisible to conventional models. But this shift also introduces new complexity around explainability, bias, and regulatory scrutiny. For risk and compliance leaders at credit unions and community banks, the goal isn't to chase the latest algorithm. It's to understand where ML genuinely improves outcomes, where it creates liability, and how to deploy it responsibly within today's regulatory environment.
Maintain 100% NCUA & OCC Audit Readiness
Monitor regulatory updates 24/7, check internal credit policies, and generate compliance trails with Erina (AI Regulatory Agent).
Table of Contents
- How does machine learning change credit assessment?
- Key machine learning techniques used in credit assessment
- Balancing model performance, fairness, and explainability
- Regulatory frameworks and risk controls for ML in credit
- A practical path for credit unions and community banks
- How RiskInMind can support your ML credit transformation
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| ML boosts accuracy and inclusion | Machine learning expands access and sharpens risk detection in credit assessment for smaller institutions. |
| Fairness and explainability are essential | Achieving regulatory compliance means balancing model performance with transparent, fair processes. |
| No single metric or model is definitive | Effective credit assessment relies on a mix of ML techniques, fairness metrics, and ongoing human review. |
| Regulatory frameworks guide safe adoption | Following NIST, NCUA, and EU AI Act standards helps ensure both innovation and compliance in machine learning credit models. |
| Start with pilot projects | Launching small-scale, explainable ML pilots with human oversight enables safe, scalable adoption. |
How does machine learning change credit assessment?
Traditional credit assessment relies on rule-based scorecards, most commonly FICO-style models that weight a fixed set of variables: payment history, utilization, length of credit history, and similar factors. These models are interpretable and auditable, but they are also static. They don't adapt to changing economic conditions, and they struggle with thin-file borrowers who lack sufficient credit history to generate a meaningful score.
Machine learning changes this by enabling AI-powered risk intelligence that continuously learns from new data, extracts non-linear relationships between variables, and adapts risk strategies over time. Recent research demonstrates that hybrid ML frameworks, combining neural networks for feature extraction (such as recurrent neural networks), ensemble methods like LightGBM for prediction, and reinforcement learning for dynamic risk control strategies, materially outperform traditional models on both accuracy and portfolio stability metrics.
For community banks and credit unions, the practical implications are substantial:
- Thin-file inclusion: ML models can incorporate alternative data sources, such as rent payments, utility history, or cash flow patterns, enabling fairer access for borrowers underserved by conventional scoring.
- Adaptive risk modeling: Unlike static scorecards, ML models update as economic conditions shift, reducing lag between real-world changes and model outputs.
- Richer feature extraction: Neural networks identify complex relationships across dozens of variables simultaneously, capturing risk signals that simple regression models miss.
The table below illustrates the key contrasts between traditional and ML-based credit assessment approaches.
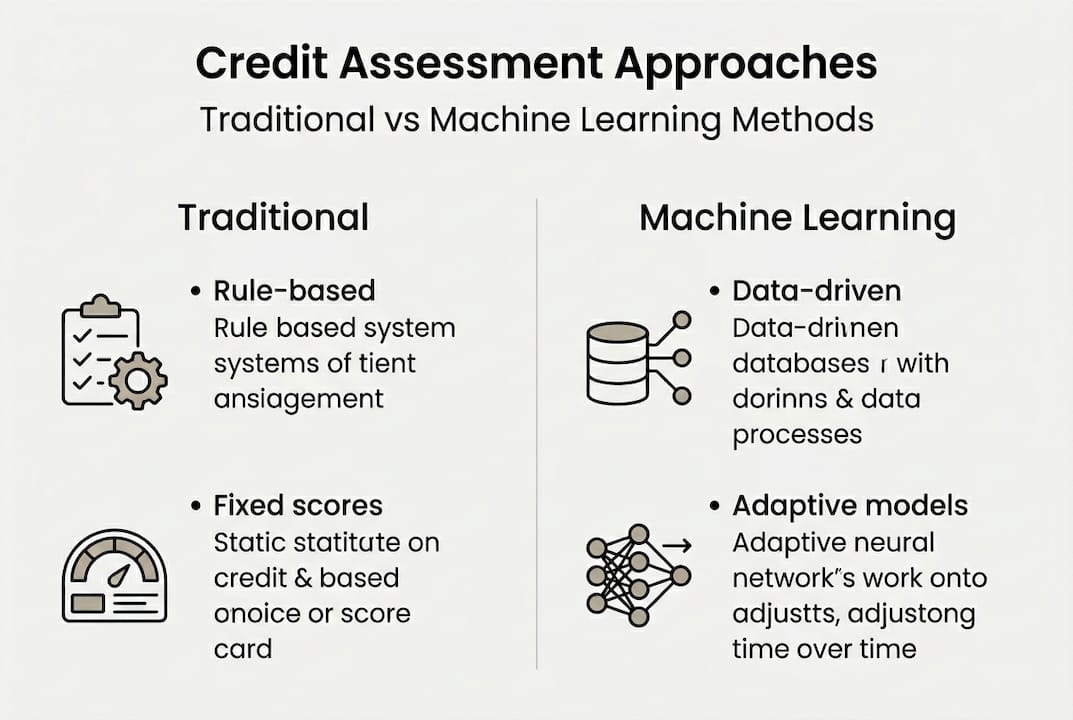
| Criteria | Traditional methods | ML-based approaches |
|---|---|---|
| Accuracy | Moderate | High (AUC improvements common) |
| Fairness | Variable, often unchecked | Measurable, but requires active management |
| Thin-file inclusion | Limited | Significantly improved |
| Model complexity | Low | Medium to high |
| Regulatory scrutiny | Established | Increasing, evolving guidance |
The disruption here isn't just technical. It's strategic. Smaller institutions that adopt ML thoughtfully can compete for borrower segments that larger banks have historically dominated.

Key machine learning techniques used in credit assessment
Understanding which ML techniques are actually in use helps you evaluate vendor claims, ask better questions of your data science teams, and make informed governance decisions. Common ML techniques in credit risk include logistic regression, decision trees, random forests, support vector machines (SVM), and neural networks, with metaheuristic feature selection methods improving prediction accuracy on benchmark datasets like the UCI German Credit dataset.
Here is a practical overview of each method and where it fits in credit assessment:
| Technique | Description | Common use in credit | Typical benefits |
|---|---|---|---|
| Logistic regression | Linear probability model | Baseline scoring, adverse action | Interpretable, auditable |
| Decision trees | Rule-based branching logic | Segment-level underwriting | Visual, easy to explain |
| Random forests | Ensemble of decision trees | Default prediction | High accuracy, robust |
| SVM | Hyperplane-based classifier | Binary default/no-default | Works well on smaller datasets |
| Neural networks | Multi-layer pattern recognition | Complex feature extraction | Best on large, rich datasets |
Beyond individual techniques, feature selection using metaheuristic methods, such as genetic algorithms or particle swarm optimization, helps identify which variables actually contribute predictive value and prunes those that introduce noise or bias. This step is often overlooked but is critical for model quality.
Introducing ML into an existing credit assessment pipeline requires a structured approach. Here are the steps most institutions follow:
- Audit your current data: Identify gaps, inconsistencies, and bias-prone variables in your existing credit files.
- Define performance targets: Set clear thresholds for accuracy (AUC, F1), fairness, and explainability before model selection.
- Start with interpretable models: Logistic regression or decision trees provide a defensible baseline before escalating to ensemble or neural methods.
- Validate on out-of-sample data: Test on data the model hasn't seen, including recent periods that reflect current economic conditions.
- Document everything: Model cards, validation reports, and bias audits are regulatory requirements, not optional steps.
The AI Credit Memo Generator automates documentation that would otherwise slow down this process. For teams ready to test ML underwriting in practice, the AI Loan Assessor demo provides a hands-on look at how these techniques perform on real credit scenarios.
Pro Tip: Always validate new features on held-out historical data and check for overfitting before moving any model into production. A model that looks strong on training data but degrades on recent data is a compliance risk, not just a technical one.
Balancing model performance, fairness, and explainability
This is where ML credit assessment gets genuinely difficult. Higher predictive accuracy, measured by AUC or F1 score, often comes at a cost to fairness or transparency. ML boosts AUC and F1, but achieving a balance between performance, fairness metrics like demographic parity, and explainability tools like SHAP and LIME remains an open challenge. No single fairness metric satisfies all goals simultaneously.
"No single fairness metric satisfies all goals, and regulatory standards remain stringent."
This matters operationally. Your examiners will ask how the model treats protected classes. Your legal team will want adverse action explanations. Your board will want to know whether the model is making decisions that a human could reasonably verify.
Explainable AI (XAI) methods address part of this challenge:
- SHAP (SHapley Additive exPlanations): Assigns each input variable a contribution score for each individual prediction, making it possible to explain why a specific applicant was declined.
- LIME (Local Interpretable Model-Agnostic Explanations): Builds a simplified local model around any given prediction to approximate what the complex model is doing at that point.
- Rebaselining SHAP: An adaptive approach that recalibrates SHAP values as models drift over time, keeping explanations aligned with current model behavior.
Common compliance pain points in this area include:
- Bias testing across protected class proxies, even when those variables are excluded from the model
- Routine model auditing that documents fairness outcomes, not just predictive accuracy
- Generating adverse action notices that meet Regulation B requirements without revealing proprietary model logic
- Maintaining human oversight at points where model confidence is low or outcomes are borderline
The SHAP and LIME explainability capabilities embedded in modern platforms make it feasible to produce audit-ready documentation without manual effort on every decision, which matters at scale.
Regulatory frameworks and risk controls for ML in credit
With those challenges laid out, what does today's regulatory playbook require? The answer is more structured than many institutions realize. NCUA guidance aligns with broader federal expectations from the OCC (SR 11-7 and OCC 2011-12) and international frameworks, requiring explainability, bias testing, model validation, and human oversight for ML in credit. The EU AI Act classifies AI credit scoring as high-risk, establishing a global benchmark that U.S. regulators are increasingly referencing.
The NIST AI Risk Management Framework (AI RMF) organizes requirements into four pillars that provide a practical structure for compliance programs:
- Govern: Establish policies, accountability structures, and board-level oversight for AI model use. Assign clear ownership for model risk across product and risk teams.
- Map: Identify where AI models are used in the credit lifecycle, what data they consume, and which regulatory obligations apply at each point.
- Measure: Quantify model performance, fairness, and drift using defined metrics. Document baseline performance and re-evaluate at scheduled intervals.
- Manage: Implement controls for model updates, bias remediation, and incident response. Ensure human-in-the-loop overrides are available and exercised where warranted.
For credit unions specifically, the FICO limitations in ML credit context adds urgency. Members who would be declined under traditional scoring may qualify under ML-augmented review, but only if the model and its governance structure are sound enough to withstand examiner scrutiny.
Pro Tip: Prepare for regulator scrutiny by scheduling quarterly reviews of your explainability outputs and bias metrics. Regulators are not just asking whether your model works. They are asking whether you understand why it works and what you would do if it stopped.
A practical path for credit unions and community banks
Let's step back and look at what actually works in the real world, rather than what the technology vendors and conference keynotes suggest.
Small institutions have a structural advantage that is rarely discussed. Trust. A credit union that deploys ML with visible human oversight and clear member communication can build a stronger fairness narrative than any large bank running a black-box model on millions of accounts. The technology amplifies human judgment. It doesn't replace it.
What most institutions get wrong is the sequencing. They invest in the algorithm before investing in governance, staff training, or model documentation. The result is a model that performs well in testing and creates regulatory exposure in production. Involving risk staff early in model selection and validation, not just at sign-off, catches these gaps before they become examination findings.
The NIST AI RMF and NCUA both encourage a risk-focused, trust-building approach to AI adoption. That framing is useful. Treat subprime ML risks as a governance problem first, not a technical one. The institutions that scale ML successfully are those that build the oversight structure before they scale the model.
How RiskInMind can support your ML credit transformation
Want a trusted technology partner for your ML journey? RiskInMind is built specifically for credit unions, community banks, and lenders navigating exactly this terrain.
Our Enterprise AI risk solutions integrate explainability, automated bias monitoring, and regulatory reporting into a single platform, so you get the performance benefits of ML without the compliance gaps. The AI Loan Assessor tool delivers real-time underwriting support with full audit trails, while the Regulatory Risk Agent keeps your compliance posture current as guidance evolves. SOC 2 certified and built for bank-grade security, RiskInMind gives your risk team the infrastructure to adopt ML confidently and scale it responsibly.
Frequently asked questions
What are the main benefits of using machine learning for credit assessment?
Machine learning enables more nuanced credit scoring, better inclusion of thin-file borrowers, and adaptive risk control strategies that static scorecards cannot replicate. It also surfaces complex risk signals across a broader set of variables than traditional models process.
How do regulators view AI-based credit scoring?
Regulators require high explainability, bias testing, and model validation, and the EU AI Act classifies AI credit scoring as high-risk, a standard that U.S. regulators are increasingly referencing in their own examination frameworks.
Which fairness metrics are mandatory in ML credit models?
No single fairness metric is mandated by regulation. A mix is applied, with institutions required to document trade-offs between metrics like demographic parity, equalized odds, and predictive parity depending on the credit product and regulatory context.
What is concept drift and why does it matter in ML credit models?
Concept drift occurs when the statistical relationship between input variables and credit outcomes changes over time, often due to economic shifts or behavioral changes among borrowers. Without regular model recalibration and adaptive XAI methods, drift causes model accuracy and fairness metrics to degrade silently.
How should community banks start adopting ML for credit assessment?
Start with a pilot on a defined loan segment, prioritize interpretable models first, and build human review into every decision point. NIST AI RMF alignment from day one ensures that your governance structure scales with your model complexity rather than lagging behind it.
Recommended
- Transforming Credit Union Growth with AI-Powered Risk Intelligence | RiskInMind
- Credit RiskinMind AI Credit Memo Generator | RiskInMind
- CRE Loan Risk Predictor - AI Commercial Real Estate Analysis | RiskInMind
- Stopping the Next 1st Choice: How RiskinMind.ai Helps Credit Unions Catch Trouble Before Failure | RiskInMind
- Machine learning in fintech 2026: optimizing crypto trading